
windows+eclipse+maven+华为MRS服务(wordcount举例)
准备工作:
- Eclipse
- Maven
- JDK1.8
- hadoop集群(我使用的是华为的MRS服务)
安装JDK+Eclipse
安装Maven
- 官方下载
- 解压后放在喜欢的文件夹中,并设置好系统PATH路径
- win+cmd 输入 mvn --version检测是否安装成功
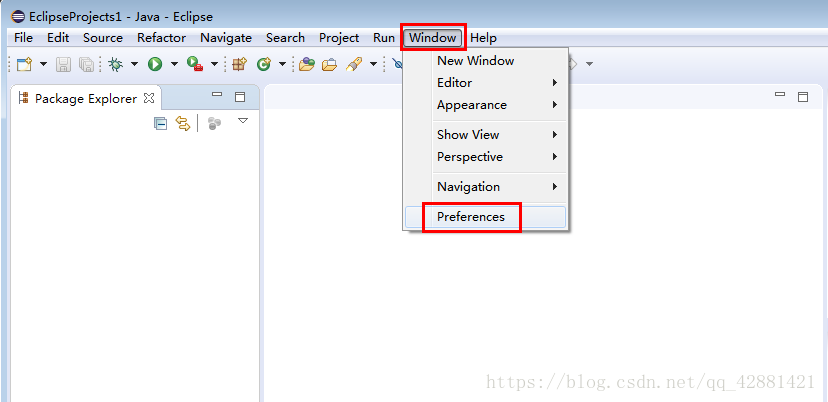
配置eclipse的Maven
- eclipse-->Window-->Preferences
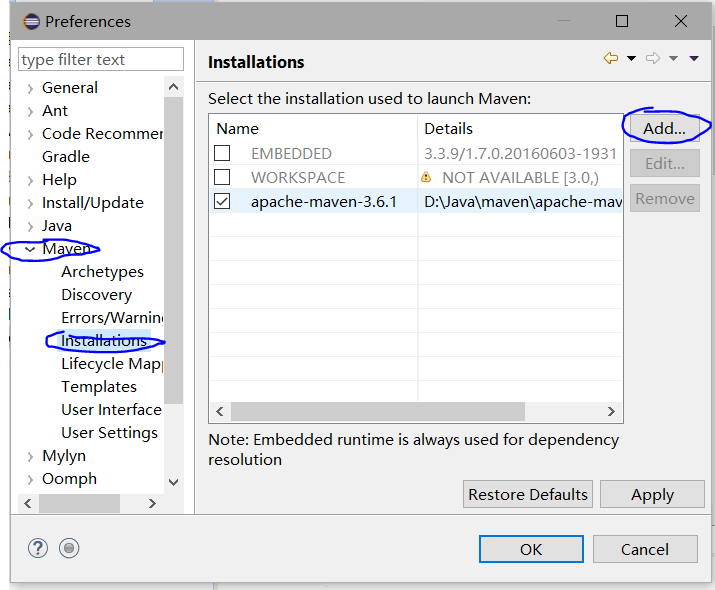
- 点击add后,定位到Maven所在的目录finish
- 将maven选项勾选上
- User Settings 将Global Setting的路径定位到/Maven目录/conf/settings.xml
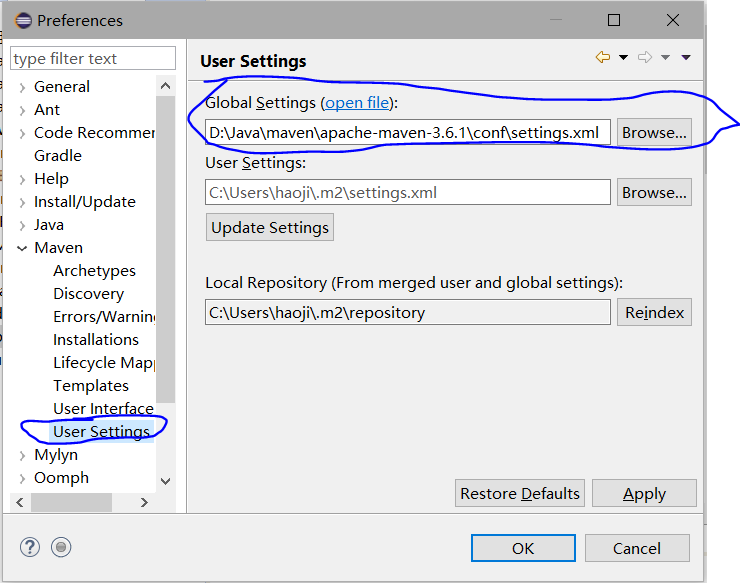
- 点击OK
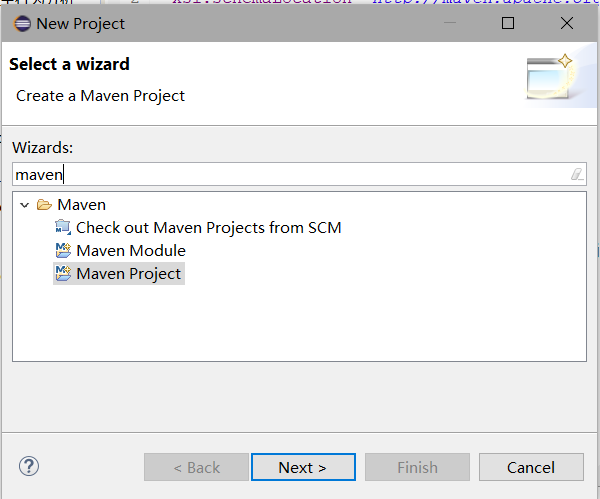
新建Maven工程
File-->New-->Project
输入Maven,点击Maven Project ,点击Next
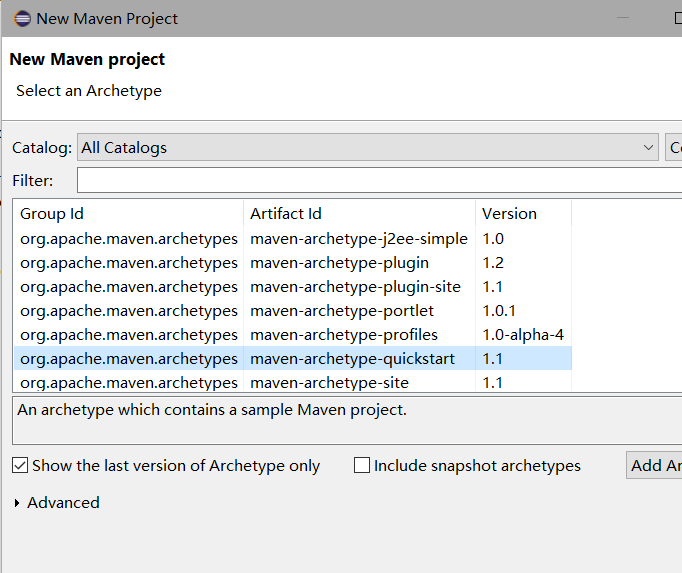
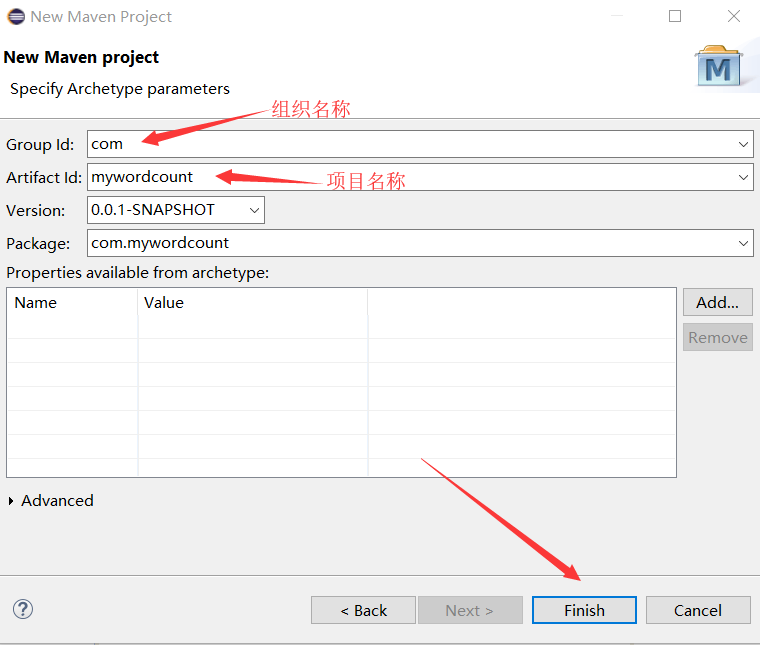
构建完成后再目录结构中,修改pos.xml配置文件
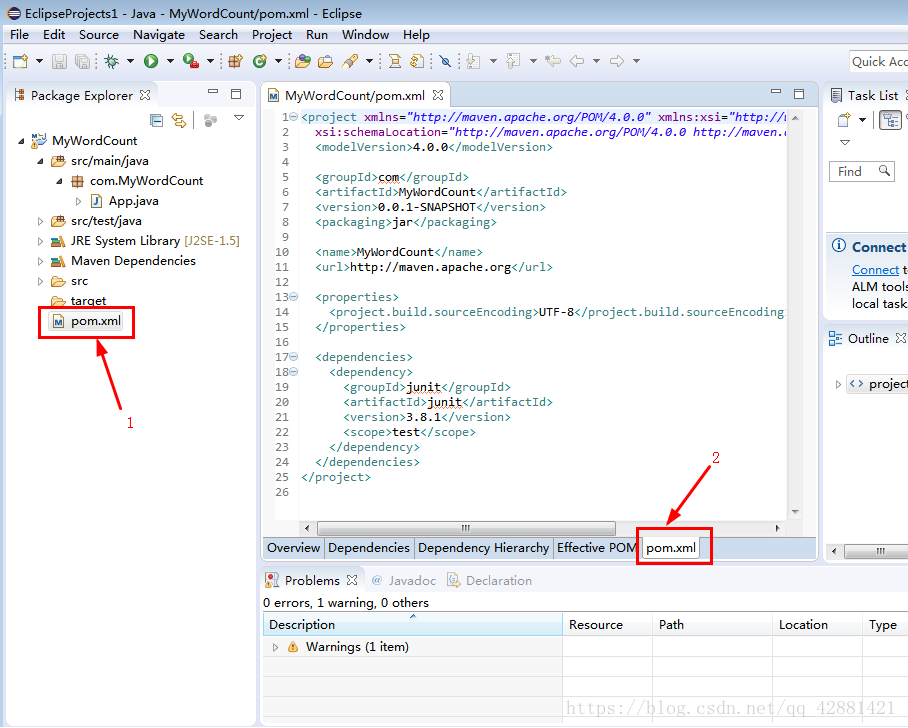
再
<name>MyWordCount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- main()所在的类,注意修改 -->
<mainClass>com.MyWordCount.WordCountMain</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
ctrl+s保存,右键项目Refresh 刷新。
这个时候会下载相应的依赖包,可能会很久
我们要写的主程序是在src/main/java中com.MyWordCount包下,可以把原来的文件删除,然后开始写我们需要的Wordcount程序
WordCountMain
package com.MyWordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception {
//1.创建一个job和任务入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountMain.class); //main方法所在的class
//2.指定job的mapper和输出的类型<k2 v2>
job.setMapperClass(WordCountMapper.class);//指定Mapper类
job.setMapOutputKeyClass(Text.class); //k2的类型
job.setMapOutputValueClass(IntWritable.class); //v2的类型
//3.指定job的reducer和输出的类型<k4 v4>
job.setReducerClass(WordCountReducer.class);//指定Reducer类
job.setOutputKeyClass(Text.class); //k4的类型
job.setOutputValueClass(IntWritable.class); //v4的类型
//4.指定job的输入和输出
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5.执行job
job.waitForCompletion(true);
}
}
WordCountReducer
package com.MyWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// k3 v3 k4 v4
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {
//对v3求和
int total = 0;
for(IntWritable v:v3){
total += v.get();
}
//输出 k4 单词 v4 频率
context.write(k3, new IntWritable(total));
}
}
WordCountMapper
package com.MyWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 泛型 k1 v1 k2 v2
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
//数据: I like MapReduce
String data = value1.toString();
//分词:按空格来分词
String[] words = data.split(" ");
//输出 k2 v2
for(String w:words){
context.write(new Text(w), new IntWritable(1));
}
}
}
编译打包
win+cmd,进入到这个项目的目录中:******/MyWordCount
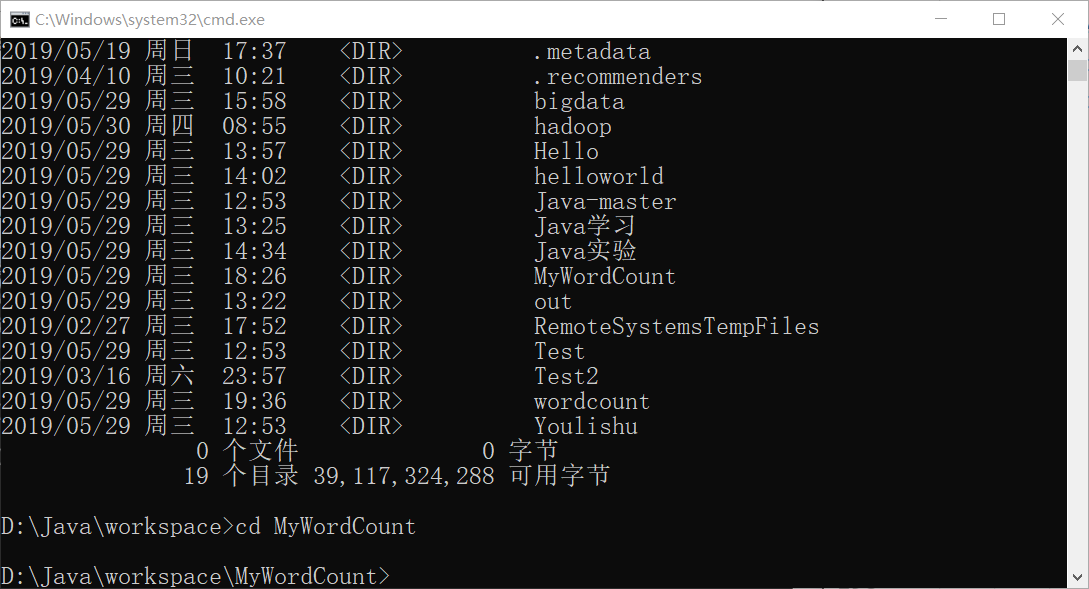
执行mvn打包命令: mvn clean package
注意:要保持网络畅通,因为项目打包时会下载一些文件。
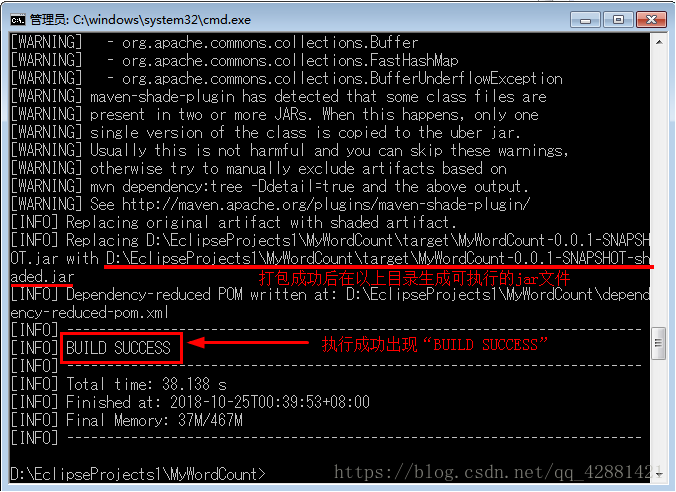
回到Eclipse在target 刷新就能看到生成好的jar文件了
使用华为云MRS服务测试程序
确定已经完成了MRS服务订购安装,OBS桶的搭建
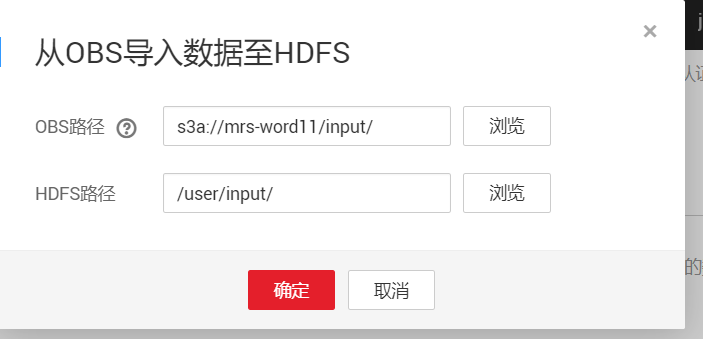
服务列表-->对象储存服务-->桶(注意桶和MRS必须在同一个大区)-->对象-->新建文件夹(program)和新建文件夹(input)
进入这两个文件夹,并上传刚才打包好的jar文件,和需要运行的文本文件
服务列表-->MapReduce服务-->现有集群-->进入-->文件管理-->导入数据
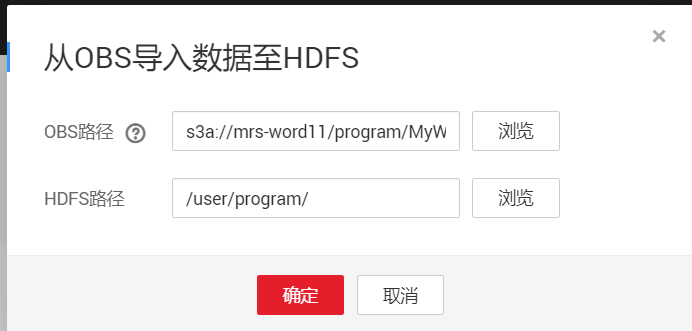
作业管理-->添加
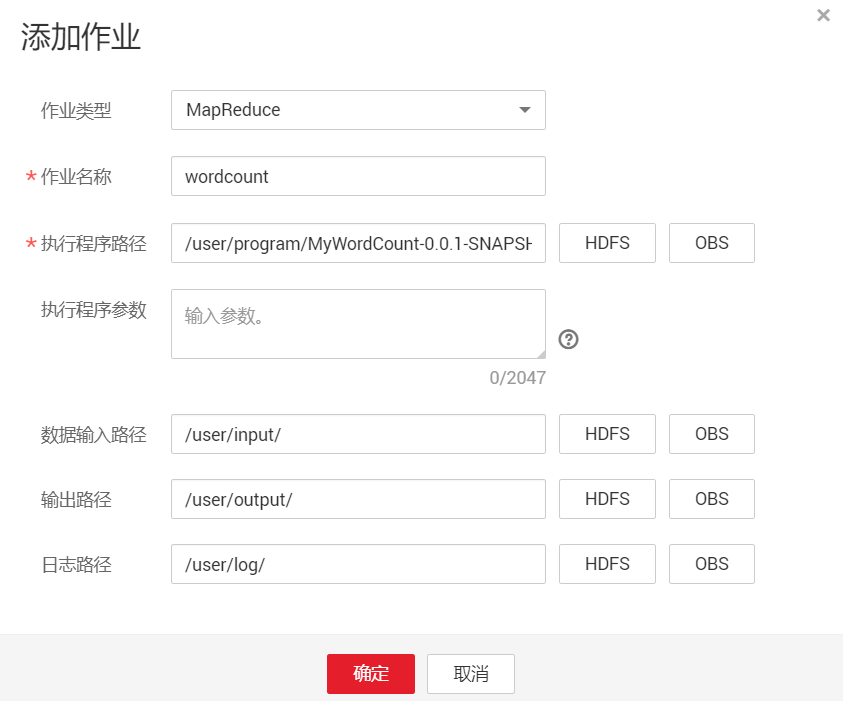
执行参数可以不用填写
hadoop jar ../MyWordCount-0.0.1-SNAPSHOT.jar MyWordCount /input /output
这个命令系统会自动生成,直接点击确定即可。
注意output文件夹一定不能存在,需要由程序自行建立,否则会报错
可以查看日志,来看程序运行情况,以及报错,最后的结果是储存在hdfs中了,我们再按照前面步骤,将其导出至obs中,就可以进行结果的下载了。
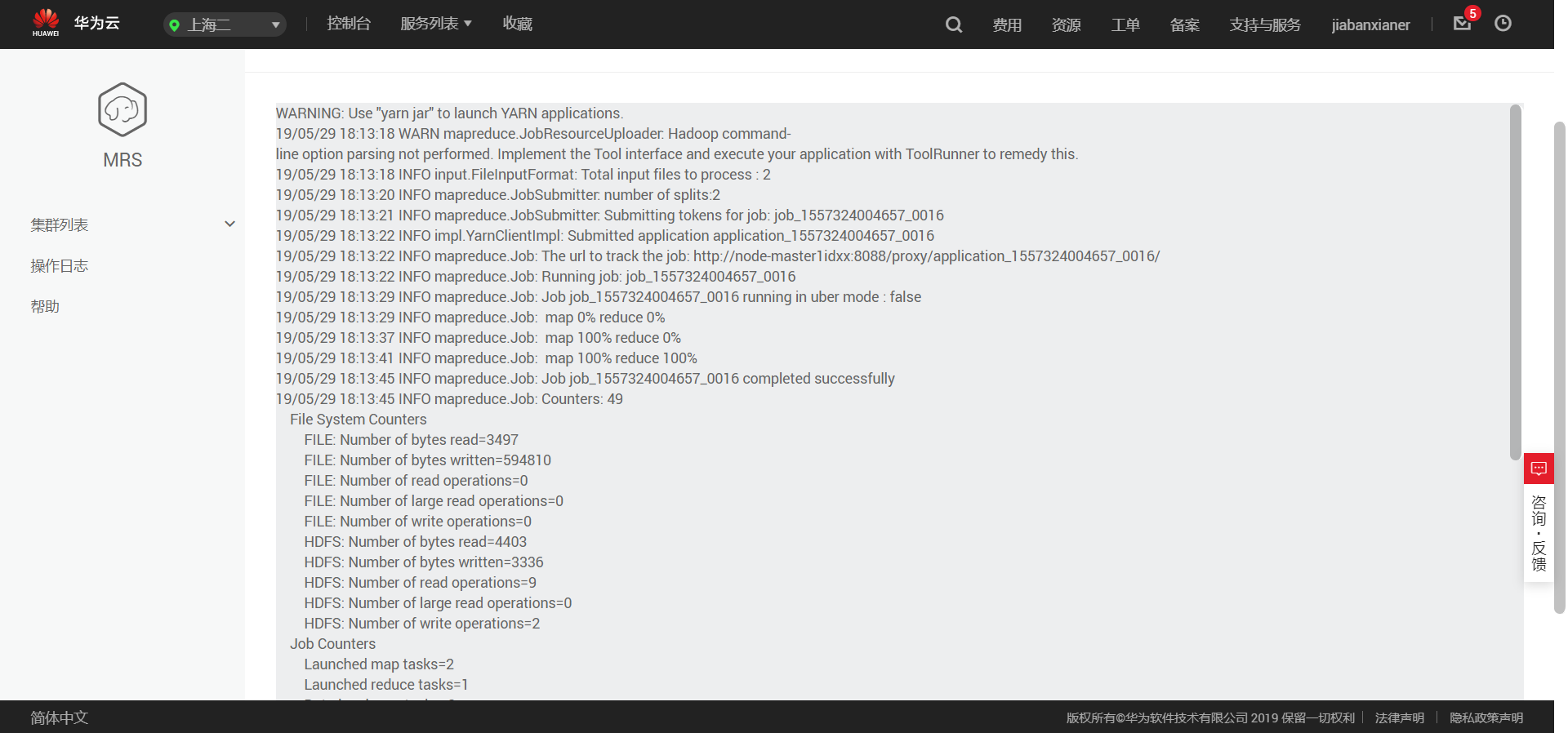
目前解决的问题只有这么多,比较大的坑点一个是本地程序的打包过程,还有就是华为MRS服务似乎没有办法直接从obs中调用程序和数据,必须要转移到hdfs中,才可以使用。
本文链接:
/archives/windowseclipsemaven%E5%8D%8E%E4%B8%BAmrs%E6%9C%8D%E5%8A%A1wordcount%E4%B8%BE%E4%BE%8B
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
Hao.Jia's Blog!
喜欢就支持一下吧