
【超简单AI教程】三行代码带你掌握糖尿病问题分类!
【超简单AI教程】三行代码带你掌握糖尿病问题分类!
前言
如果你对人工智能感兴趣,但感觉自己处于陌生的领域,那么你来对地方了。刚刚接触的同学往往都被负责的公式和代码而劝退,在这个教程中,我们将用“三行代码”实现一个人工智能案例,并开启你对人工智能的探索之旅。
此次案例来源于“天池”人工智能比赛:CHIP2023-中文糖尿病问题分类
任务描述
任务详情
随着互联网的快速发展,庞大的二型糖尿病患者和高危人群对糖尿病专业信息获取的需求日益突出,糖尿病作为一种典型慢性疾病已成为全球重大公共卫生挑战之一,糖尿病自动问答服务对患者和高危人群的日常健康服务也发挥着越来越重要的作用。
中文糖尿病问题分类评测任务旨在自动为患者提出的有关糖尿病问题进行分类。
该任务将有助于增强搜索结果的性能并推动糖尿病自动问答服务的发展。
参赛者需要预测测试集中糖尿病问题对应的分类,预测完成后需将测试数据集空缺的类别标签数据进行填充。评价环节仅对填充的数据进行误差分析,得出预测表现得分。
数据介绍
评测数据集包含的中文糖尿病问题一共分为6类,包括诊断、治疗、常识、健康生活方式、流行病学、其他。
数据以 6:1:1 的比例划分为训练集、验证集和测试集。
总计6000条数据。数据集都是以 .txt 格式存储。
训练集、验证集和测试集包含question和label,分类数据集包含class和label。
参赛者需要预测测试集中糖尿病问题对应的分类,预测完成后需将测试数据集空缺的类别标签数据进行填充。
数据形式
训练集/验证集如下(数据集中没有存储表头question和label):
question | label | |
|---|---|---|
糖尿病会引起眼睛水肿吗 | \t | 4 |
糖尿病患者能用党参泡水喝吗 | \t | 3 |
糖尿病人吃菠菜好吗 | \t | 3 |
孕妇得了糖尿病怎么办 | \t | 1 |
分类数据集如下(数据集中没有存储表头class和label):
class | label | |
|---|---|---|
Diagnosis | \t | 0 |
Treatment | \t | 1 |
Common Knowledge | \t | 2 |
healthy lifestyle | \t | 3 |
Epidemiololgy | \t | 4 |
Other | \t | 5 |
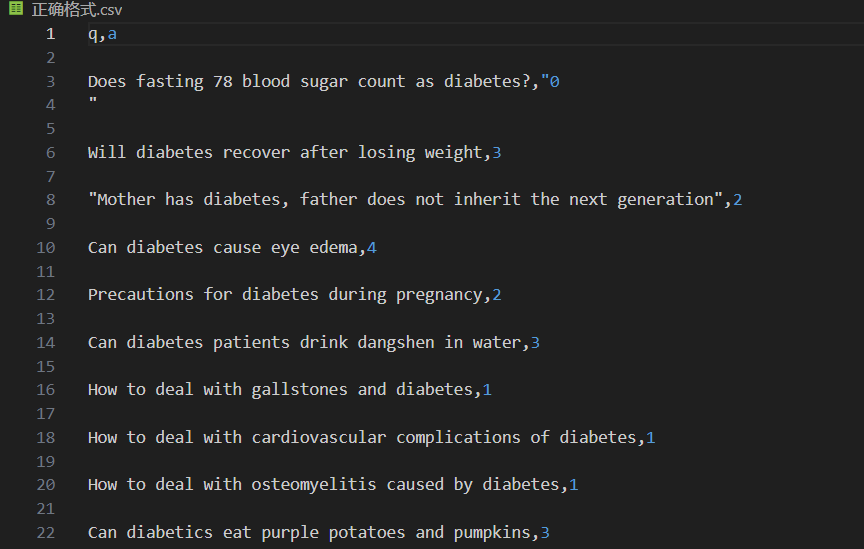
数据样例
评测网站发布测试集(数据集中没有存储表头question和label):
question | label | |
|---|---|---|
糖尿病患者可以吃西瓜吗 | \t | (空) |
参赛队伍需要预测测试集中糖尿病问题对应的分类,预测完成后需将测试数据集空缺的类别标签数据进行填充(同样不需要存储表头question和label)
question | label | |
|---|---|---|
糖尿病患者可以吃西瓜吗 | \t | 3 |
评价指标
该任务使用准确率(Acc,Accuracy)作为整体排名标准,公式如下:

“三行代码”实现
本章节将介绍如何使用AutoGluon框架快速实现上述文本分类任务。
环境配置
要想使用AutoGluon,需要在电脑上配置好AutoGluon所需环境。
本文需要的前置依赖环境请根据其他教程进行配置:
anaconda环境配置:https://blog.csdn.net/qq_42324086/article/details/108868009
深度学习环境配置:https://cloud.tencent.com/developer/article/1667196
其他配置教程请自行搜索。
需要的前置依赖:anaconda环境,Nvidia显卡驱动,cuda环境。
注意cuda版本⚠️
配置AutoGluon环境
打开anaconda输入代码创建虚拟环境
conda create -n myenv python=3.9 -y # 创建环境
conda activate myenv # 激活环境通过pip下载带有GPU支持的pytorch
注意cuda版本⚠️
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 检验pytorch环境是否安装成功
import torch
print(torch.cuda.is_available()) # Should be True
print(torch.cuda.device_count()) # Should be > 0安装AutoGluon包
pip install autogluon数据预处理

由介绍可知,多模态模型适用于本场比赛
根据介绍可知,我们需要把文本和标签转化为csv格式,并设置question和label
 同时,文本分类问题需要对词句进行编码,中文编码可能存在问题,一般要使用英文形式进行处理。
同时,文本分类问题需要对词句进行编码,中文编码可能存在问题,一般要使用英文形式进行处理。
综上,确定了我们的数据预处理任务:
将中文数据翻译成为英文数据
将txt文件读取成pandas的DataFrame形式
为了方便大家使用,这里直接提供了处理完成的csv文件:
处理好的训练集:CHIP2023-中文糖尿病问题分类_train.csv
处理好的验证集:CHIP2023-中文糖尿病问题分类_val.csv
模型训练
短短几行代码即可调用 autogluon来实现文本分类任务
from autogluon.tabular import TabularDataset,TabularPredictor
from autogluon.multimodal import MultiModalPredictor
train_data = TabularDataset("/root/CHIP2023-中文糖尿病问题分类_train.csv") # 加载数据,需要将路径替换为自己的路径
predictor = MultiModalPredictor(label='a',path='AIDC--NLP').fit(train_data,presets='best_quality') # 标签列为'a',构造预测模型 模型成功的识别出我要进行的是分类任务,并且会自动调用显卡进行加速。
模型成功的识别出我要进行的是分类任务,并且会自动调用显卡进行加速。

模型验证
test_df = pandas.read_csv('CHIP2023-中文糖尿病问题分类_val.csv') # 加载数据,需要将路径替换为自己的路径
predictions = predictor.predict(test_df)
eval_metrics = predictor.evaluate(test_df)大家可以自行根据文档的说明进行测试,看看准确率是多少。
参考资料
AutoMl网站:https://auto.gluon.ai/stable/install.html
李沐老师对AutoMl的介绍: https://www.bilibili.com/video/BV1rh411m7Hb/?spm_id_from=333.999.0.0&vd_source=8960208bce609f71774cff2cecf47e59
{kind=link}
{kind=link}