
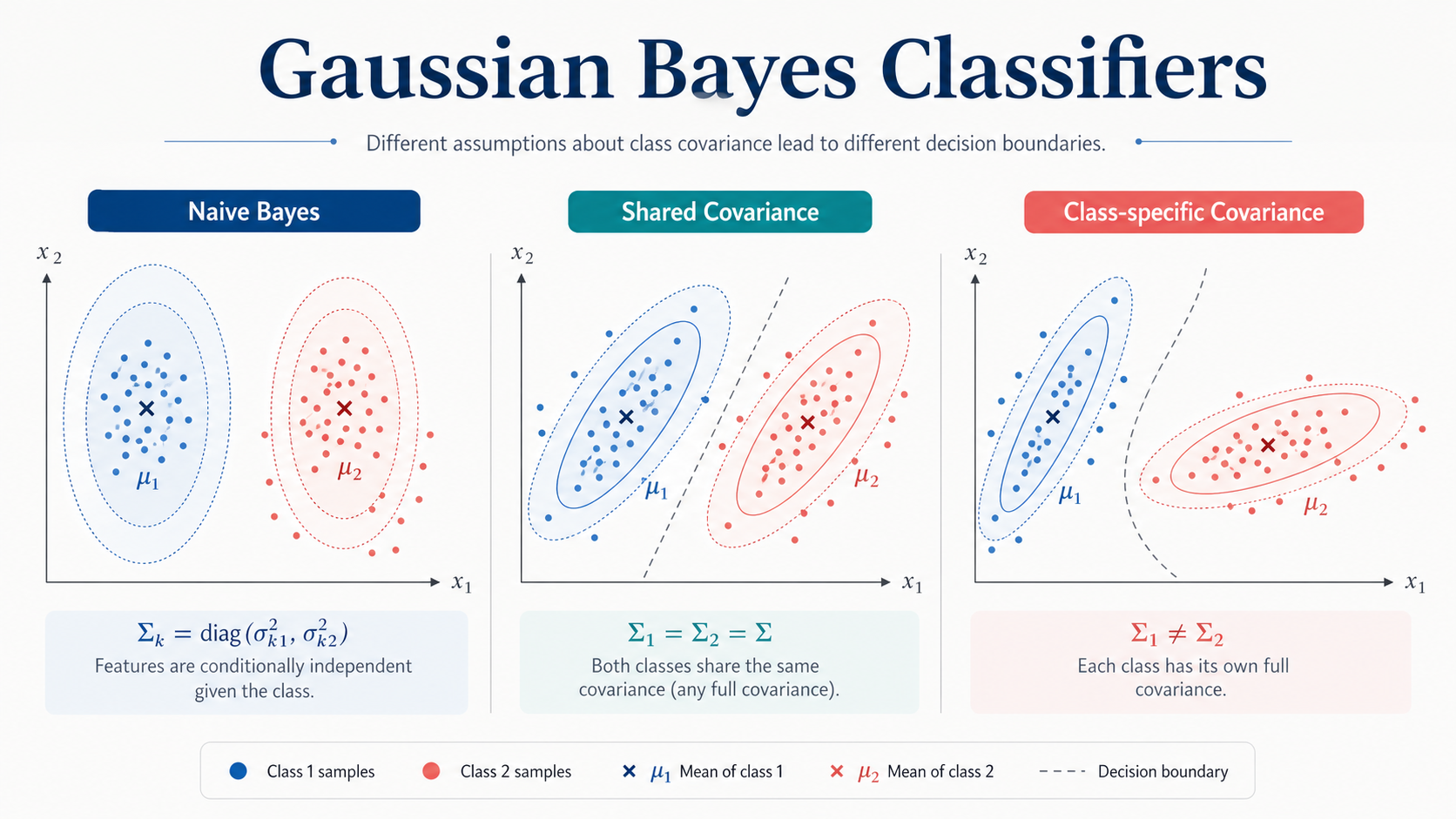
三种 Gaussian Bayes 分类器:Naive、Shared Covariance 与 Class-specific Covariance
三种 Gaussian Bayes 分类器:Naive、Shared Covariance 与 Class-specific Covariance
在这个实验中,我们比较了 Logistic Regression 和三种 Gaussian Bayes 分类器:
- Naive Bayes
- Gaussian Bayes with shared covariance
- Gaussian Bayes with class-specific covariance
这三种 Gaussian Bayes 模型的共同点是:它们都使用 Bayes rule 进行分类,并且都假设每个类别的数据服从高斯分布。
它们的区别在于:如何建模每个类别的协方差矩阵。
更直观地说:
对每个类别画一个“高斯云团”,新样本落在哪个类别云团里的概率更大,就判给哪个类。
三种模型的区别就是:这个“高斯云团”的形状怎么画。
1. 共同基础:Bayes Rule
给定一个输入样本:
我们希望判断它属于哪个类别:
Bayes rule 给出:
其中:
- p(c_k|\mathbf{x}):给定样本 \mathbf{x} 后,它属于类别 c_k 的后验概率
- p(\mathbf{x}|c_k):类别 c_k 下观察到样本 \mathbf{x} 的概率,即 likelihood
- p(c_k):类别 c_k 的先验概率
- 分母是归一化项
分类时,我们只关心哪个类别的后验概率最大:
由于分母对所有类别都一样,所以可以只比较分子:
为了避免多个很小的概率相乘导致数值下溢,代码中通常使用 log-space:
对应代码:
log_joint[:, k] = log_lik + np.log(self.priors_[k])
return self.classes_[self.predict_proba(X).argmax(axis=1)]
类别先验由训练集中类别比例估计:
self.priors_ = counts / len(y)
对应公式:
其中 n_k 是类别 c_k 的样本数,n 是总样本数。
2. 直观理解:每个类别是一团高斯云
假设我们只有两个特征:
x1 = 肿瘤半径
x2 = 肿瘤纹理
每个类别,比如 benign / malignant,都可以看成二维平面上的一团点。
Gaussian Bayes 要估计两件事:
- 这团点的中心在哪里
- 这团点是怎么散开的
中心由均值表示:
散开方式由协方差矩阵表示:
代码中,每个类别的均值估计为:
self.means_[k] = Xk.mean(axis=0)
对应公式:
三种 Gaussian Bayes 模型的区别就在于:\Sigma_k 怎么设。
3. Naive Bayes:不看特征相关性
3.1 核心假设
Naive Bayes 的核心假设是:
给定类别后,各个特征相互独立。
也就是说:
如果每个特征都服从一元高斯分布:
那么:
取 log 后:
一元高斯的 log density 为:
因此 Naive Bayes 的分类规则是:
3.2 协方差矩阵形式
Naive Bayes 等价于假设每个类别的协方差矩阵是对角矩阵:
非对角线元素为 0,表示模型不考虑不同特征之间的相关性。
通俗地说,Naive Bayes 只看:
半径自己怎么变?
纹理自己怎么变?
但不看:
半径变大时,纹理会不会也一起变大?
所以它画出来的“高斯云团”是轴对齐的椭圆,不能倾斜。
3.3 代码实现
创建模型:
nb = GaussianBayesClassifier(shared_cov=False, diagonal=True)
关键参数是:
diagonal=True
表示使用对角协方差矩阵。
训练时估计每个类别、每个特征的方差:
var_k = Xk.var(axis=0) if len(Xk) > 1 else global_var
self.vars_[k] = np.maximum(var_k, 1e-6)
对应公式:
预测时计算各特征一元高斯 log density,并对特征维度求和:
log_lik = norm.logpdf(
X, loc=self.means_[k], scale=np.sqrt(self.vars_[k])
).sum(axis=1)
对应公式:
3.4 优缺点
Naive Bayes 的特点:
- 参数少
- 小样本时稳定
- 方差低
- 忽略特征相关性
- 偏差相对较高
4. Shared Covariance Gaussian Bayes:看相关性,但所有类别共用一种形状
4.1 核心假设
Shared covariance Gaussian Bayes 假设每个类别都是多元高斯分布:
注意这里所有类别共享同一个协方差矩阵:
不同类别可以有不同的中心:
但它们的“云团形状”一样。
通俗地说:
benign 和 malignant 的中心可以不同,
但椭圆的方向、胖瘦、形状相同。
4.2 多元高斯公式
多元高斯 density 为:
取 log:
分类时比较:
由于 shared covariance 中 \Sigma 对所有类别相同,所以:
和:
对所有类别一样,可以抵消。
4.3 为什么决策边界是线性的
展开二次项:
得到:
其中:
对所有类别相同,也可以抵消。
因此判别函数可以写成:
这个函数关于 \mathbf{x} 是线性的,所以 shared covariance Gaussian Bayes 对应线性决策边界,类似 LDA。
4.4 代码实现
创建模型:
gbc_s = GaussianBayesClassifier(shared_cov=True, diagonal=False)
关键参数:
shared_cov=True
diagonal=False
先对每个类别估计完整协方差矩阵:
raw = np.cov(Xk.T, bias=True)
self.covs_[k] = raw + ridge * np.eye(d)
对应:
然后做 pooled covariance:
pooled = sum(self.priors_[k] * self.covs_[k] for k in range(K))
self.covs_ = np.stack([pooled] * K, axis=0)
对应:
最后所有类别都使用同一个 \hat{\Sigma}。
4.5 优缺点
Shared covariance 的特点:
- 能考虑特征之间的相关性
- 比 Naive Bayes 更灵活
- 比 class-specific covariance 更稳定
- 决策边界是线性的
- 假设所有类别具有相同的协方差结构
5. Class-specific Covariance Gaussian Bayes:每个类别有自己的云团形状
5.1 核心假设
Class-specific covariance Gaussian Bayes 假设:
这里协方差矩阵带有类别下标 k,说明每个类别都有自己的协方差矩阵。
通俗地说:
benign 的云团可能比较圆,
malignant 的云团可能又长又斜。
每个类别都可以有自己的椭圆方向、胖瘦和形状。
5.2 多元高斯公式
因为每个类别有自己的 \Sigma_k,所以:
分类规则:
这里:
不能抵消,因为不同类别的协方差不同。
同时二次项里的:
也不能抵消,因为 \Sigma_k^{-1} 随类别变化。
因此 class-specific covariance Gaussian Bayes 的决策边界通常是二次的,类似 QDA。
5.3 代码实现
创建模型:
gbc_c = GaussianBayesClassifier(shared_cov=False, diagonal=False)
关键参数:
shared_cov=False
diagonal=False
这表示:
- 不使用 diagonal covariance
- 不共享 covariance
- 每个类别单独估计一个完整协方差矩阵
代码:
raw = np.cov(Xk.T, bias=True)
eigmin = np.linalg.eigvalsh(raw).min()
ridge = max(0.0, -eigmin) + 1e-6
self.covs_[k] = raw + ridge * np.eye(d)
对应:
其中 ridge 修正:
是为了防止协方差矩阵奇异,保证数值稳定。
预测时:
log_lik = multivariate_normal.logpdf(
X, mean=self.means_[k], cov=self.covs_[k],
allow_singular=True
)
对应:
5.4 优缺点
Class-specific covariance 的特点:
- 最灵活
- 可以表达复杂的类别分布
- 决策边界可以是二次的
- 参数最多
- 小样本时容易估计不准
- 方差高,容易过拟合
6. 三种模型对比
| 模型 | 代码设置 | 云团形状 | 是否考虑特征相关性 | 协方差假设 |
|---|---|---|---|---|
| Naive Bayes | diagonal=True | 轴对齐椭圆 | 不考虑 | 每类对角矩阵 \Sigma_k |
| Shared covariance | shared_cov=True, diagonal=False | 可倾斜椭圆 | 考虑 | 所有类别共享 \Sigma |
| Class-specific covariance | shared_cov=False, diagonal=False | 可倾斜椭圆 | 考虑 | 每类自己的 \Sigma_k |
最简单的记法:
Naive:
不看相关性。
Shared:
看相关性,但所有类别共用同一种相关结构。
Class-specific:
看相关性,而且每个类别有自己的相关结构。
7. 参数数量对比
在实验中,Breast Cancer 数据集有:
个特征,并且是二分类问题:
7.1 Naive Bayes
每个类别估计:
- d 个均值
- d 个方差
两类总共约:
个主要参数。
7.2 Shared Covariance
均值参数:
一个完整协方差矩阵的自由参数数量是:
所以主要参数约为:
7.3 Class-specific Covariance
均值参数仍然是:
但是两类各有一个完整协方差矩阵:
所以主要参数约为:
因此复杂度大致为:
8. 和实验结果的对应
实验结果:
LogReg Test Acc = 0.9561
Naive Bayes Test Acc = 0.9649
GBC shared cov Test Acc = 0.9561
GBC class cov Test Acc = 0.9211
从结果看,Naive Bayes 的测试准确率最高,Class-specific covariance 的测试准确率最低。
这可能看起来有点反直觉,因为 Naive Bayes 的独立性假设很强,而且现实中特征之间往往是相关的。
但从 bias-variance tradeoff 来看,这个结果是合理的。
Naive Bayes:
- 假设最强
- 参数最少
- 方差最低
- 小样本时更稳定
Class-specific covariance:
- 假设最弱
- 模型最灵活
- 参数最多
- 协方差估计不稳定
- 小样本时容易高方差
当前训练集大约 455 个样本,分到每类大约 200 多个。对于 30 维 full covariance 来说,每类 465 个协方差参数并不轻松。因此 class-specific covariance 容易受到估计噪声影响,导致测试集表现较差。
所以可以总结为:
Naive Bayes 赢,不是因为它的独立性假设完全正确,而是因为它用强假设换来了低方差。在当前样本量下,低方差带来的收益超过了忽略相关性带来的偏差。
9. 总结
三种 Gaussian Bayes 的核心区别不在 Bayes rule,而在协方差矩阵的假设。
Bayes rule 是共同基础:
区别在于:
如何设置。
- Naive Bayes:\Sigma_k 是对角矩阵,不考虑特征相关性
- Shared covariance:所有类别共用同一个完整 \Sigma
- Class-specific covariance:每个类别有自己的完整 \Sigma_k
最终选择哪种模型,取决于样本量、特征维度、真实分布以及 bias-variance tradeoff。
如果样本很少,强假设模型可能更好;如果样本很多,灵活模型才更可能发挥优势。
{kind=link}
{kind=link}